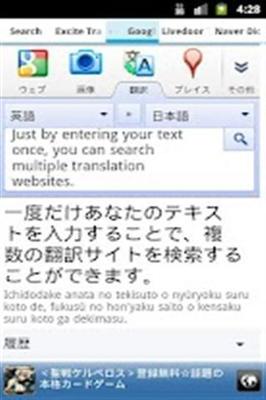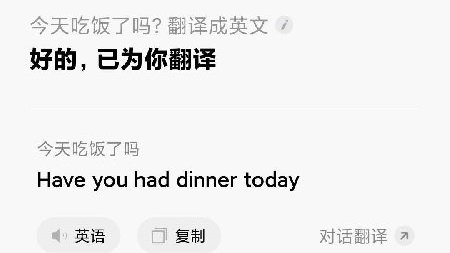
機器翻譯作為人工智能領域的重要分支,近年來在軟件開發中取得了顯著進展。從最初的基于規則的機器翻譯系統,到統計機器翻譯,再到如今基于神經網絡的深度學習翻譯模型,翻譯質量得到了質的飛躍。軟件開發者在構建翻譯系統時,充分利用大數據、云計算和先進的算法架構,使得機器翻譯在速度、準確性和語言覆蓋范圍方面都實現了巨大突破。
機器翻譯在軟件開發過程中仍面臨諸多局限。語境理解不足導致翻譯生硬,特別是在處理成語、俚語和文化特定表達時常常出現偏差。低資源語言的翻譯質量仍然較差,這主要是由于訓練數據不足所致。專業領域的術語翻譯準確性也有待提高,特別是在法律、醫療等需要精確表達的領域。
軟件開發者在應對這些挑戰時,正在探索多模態學習、遷移學習和主動學習等新技術。通過構建更完善的語言模型,引入領域知識庫,以及開發人機協作的翻譯系統,機器翻譯的質量正在持續提升。未來,隨著算法優化和數據資源的不斷豐富,機器翻譯有望在保持快速高效的同時,更好地處理語言中的微妙差異和文化內涵。